MySQL索引下推(ICP):优化查询的利器
MySQL索引下推(ICP):优化查询的利器
一、什么是索引下推
索引下推(Index Condition Pushdown,简称ICP)是MySQL 5.6版本引入的一项重要优化特性。它通过将部分WHERE条件的判断操作从MySQL服务层下推到存储引擎层来减少回表次数,从而提高查询效率。
二、工作原理
2.1 MySQL的查询架构
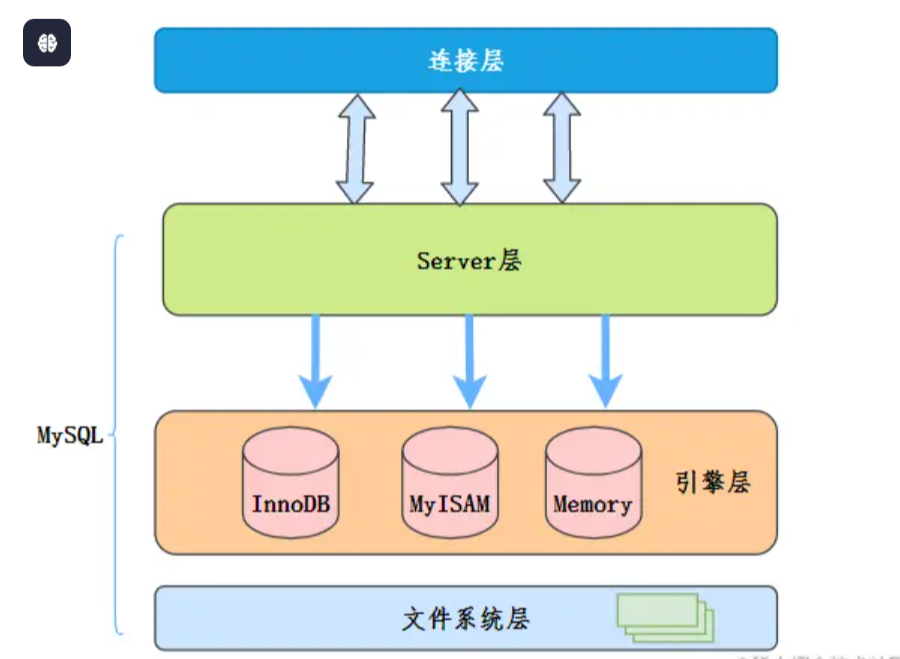
MySQL的查询处理分为两个主要层次:
-
服务层(Server Layer)
- 负责SQL解析
- 生成执行计划
- 调用存储引擎接口
-
存储引擎层(Storage Engine Layer)
- 负责数据的存储和检索
- 管理表空间
- 维护索引结构
2.2 传统查询过程(不使用ICP)
- 存储引擎层读取索引记录
- 通过索引中的主键值进行回表,读取完整的行记录
- 将记录返回给服务层
- 服务层判断记录是否满足WHERE条件
2.3 使用索引下推的查询过程
- 存储引擎层读取索引记录(不是完整行记录)
- 在存储引擎层直接利用索引中的列判断WHERE条件
- 只有在满足条件的情况下才进行回表操作
- 将满足条件的完整记录返回给服务层
使用ICP是先用where过滤了一些需要查询的数据,有效的降低了回表次数
三、实际案例分析
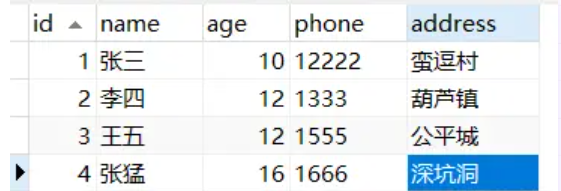
3.1 表结构设计
使用一张用户表tuser,表里创建联合索引(name, age)。
3.2 查询场景
如果现在有一个需求:检索出表中名字第一个字是张,而且年龄是10岁的所有用户。那么,SQL语句是这么写的:
SELECT * FROM users WHERE name LIKE '张%' AND age = 25;
3.3 执行过程对比
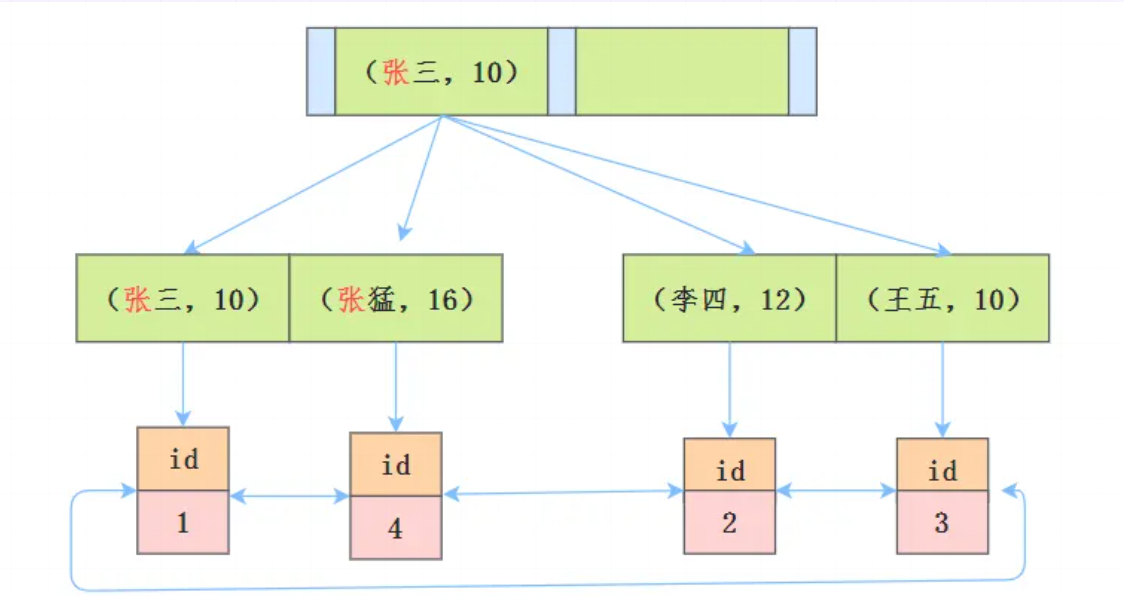
假如你了解索引最左匹配原则,那么就知道这个语句在搜索索引树的时候,只能用 张,找到的第一个满足条件的记录id为1。
那接下来的步骤是什么呢?
不使用索引下推时
- 存储引擎找到满足
name LIKE '张%'的主键id(1、4) - 对这些记录逐一回表查询完整数据
- 服务层再根据
age = 25条件过滤
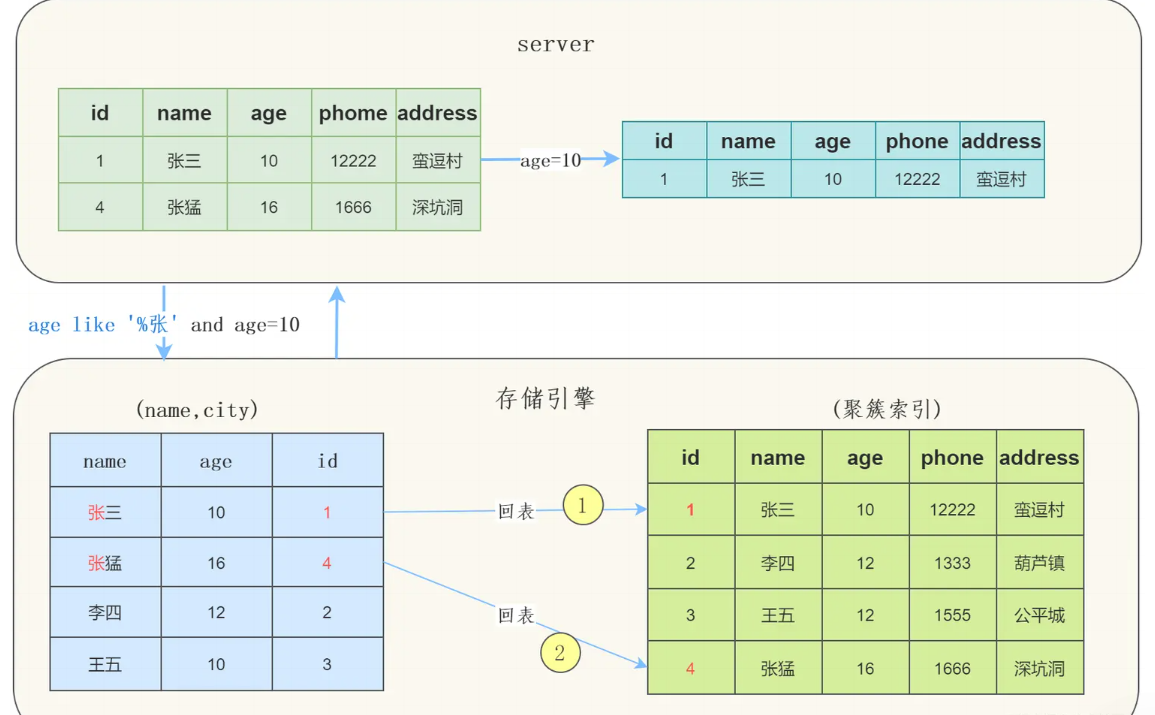
可以看到需要回表两次,把我们联合索引的另一个字段age浪费了。
缺点: 可能会进行许多不必要的回表操作
使用索引下推时
- 存储引擎在索引中找到
name LIKE '张%'的记录 - 直接在索引中判断
age = 25条件 - 只对满足年龄条件的记录进行回表
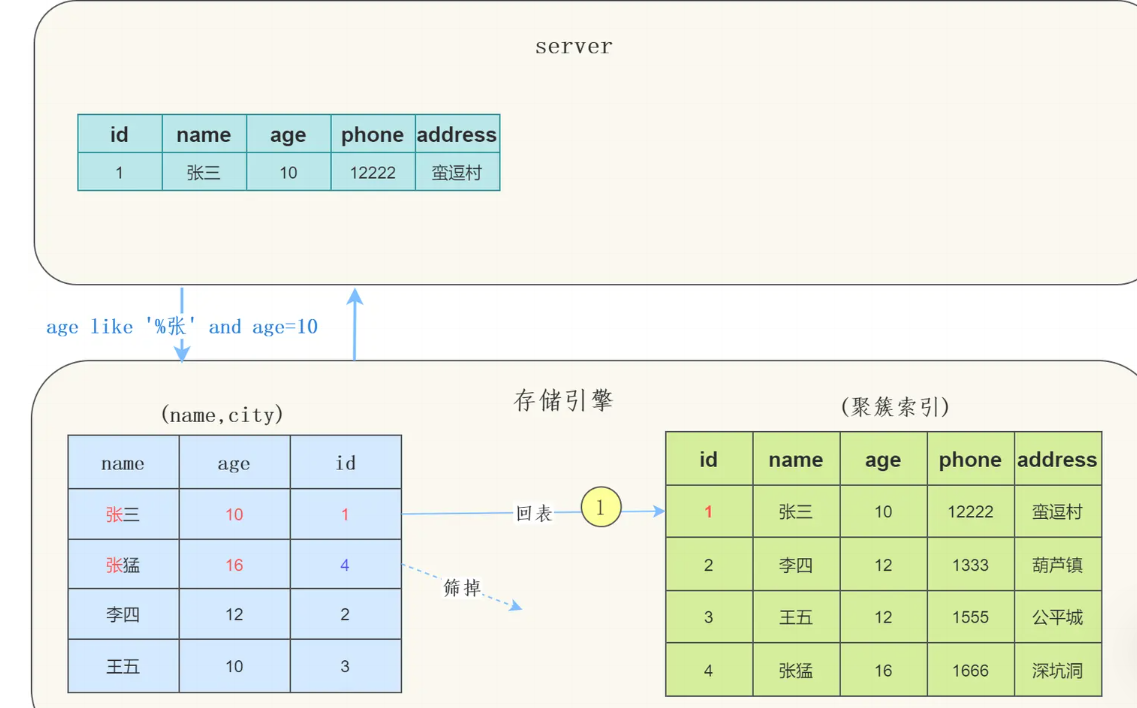
可以看到只回表了一次。
优势: 显著减少回表次数
除此之外我们还可以看一下执行计划,看到 Extra 一列里 Using index condition,这就是用到了索引下推。

四、使用条件和限制
4.1 适用条件
- 只能用于 InnoDB 和 MyISAM 存储引擎及其分区表;
- 只能用于 range、 ref、 eq_ref、ref_or_null 访问方法;
- 对 InnoDB 引擎,索引下推只适用于二级索引
(索引下推的目的是为了减少回表次数,也就是要减少IO操作。对于InnoDB的聚簇索引来说,数据和索引是在一起的,不存在回表这一说) - 引用了子查询的条件不能下推;
- 引用了存储函数的条件不能下推,因为存储引擎无法调用存储函数。
4.2 使用限制
-
不支持的情况
- 包含子查询的条件
- 使用存储函数的条件
- 使用虚拟生成列的条件
-
失效场景
- 当查询条件中的列不在索引中
- 当使用主键索引时
五、如何判断是否使用了索引下推
5.1 通过执行计划判断
EXPLAIN SELECT * FROM users WHERE name LIKE '张%' AND age = 25;
在执行计划的Extra列中,如果看到 Using index condition,说明使用了索引下推优化。
5.2 开启/关闭索引下推
-- 查看索引下推状态
SELECT @@optimizer_switch\G
-- 关闭索引下推
SET optimizer_switch='index_condition_pushdown=off';
-- 开启索引下推
SET optimizer_switch='index_condition_pushdown=on';
六、总结
索引下推是MySQL查询优化的重要特性,它通过将部分过滤操作下推到存储引擎层,有效减少了回表次数,提升了查询性能。在实际应用中,我们应该:
- 理解索引下推的工作原理
- 合理设计索引结构
- 编写优化的查询语句
- 监控查询性能
通过正确使用索引下推特性,我们可以在不改变业务逻辑的情况下,获得可观的性能提升。
本文是原创文章,采用 CC BY-NC-ND 4.0 协议,完整转载请注明来自 程序员小刘
阅读建议
评论
匿名评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果
欢迎联系