MySQL索引详解:聚簇索引与二级索引的区别及实现原理
MySQL索引详解:聚簇索引与二级索引的区别及实现原理
一、引言
在MySQL数据库中,索引是提升查询性能的关键因素。理解索引的工作原理,特别是聚簇索引(主键索引)和二级索引(辅助索引)的区别,对于数据库优化和性能调优至关重要。本文将深入探讨这两种索引的实现原理及其在查询过程中的应用。
二、索引的基本概念
2.1 什么是索引
索引是数据库中用于提高查询效率的数据结构,类似于书籍的目录。MySQL默认使用B+树作为索引的数据结构,这种结构能够有效减少数据查找的次数,提高查询效率。
2.2 索引的分类
从物理存储的角度,MySQL中的索引主要分为两类:
- 聚簇索引(主键索引)
- 二级索引(辅助索引)
三、聚簇索引与二级索引的区别
3.1 数据存储方式
让我们通过一个具体的员工表来理解两种索引的数据存储方式:
CREATE TABLE employees (
id INT PRIMARY KEY, -- 聚簇索引键
name VARCHAR(50), -- 员工姓名
department VARCHAR(50), -- 部门
salary INT, -- 薪资
hire_date DATE -- 入职日期
);
-- 创建部门薪资的二级索引
CREATE INDEX idx_dept_salary ON employees(department, salary);
- 聚簇索引(主键索引)数据存储示意图
聚簇索引的B+树结构:
[4] -- 根节点(主键值)
/ \
[2] [6] -- 内部节点(主键值)
/ \ / \
[1] [2] [5] [6] -- 叶子节点(包含完整行数据)
叶子节点存储的完整数据示例:
[1] -> {id:1, name:"张三", department:"IT", salary:8000, hire_date:"2023-01-15"}
[2] -> {id:2, name:"李四", department:"HR", salary:7000, hire_date:"2023-02-20"}
[5] -> {id:5, name:"王五", department:"IT", salary:9000, hire_date:"2023-03-10"}
[6] -> {id:6, name:"赵六", department:"HR", salary:7500, hire_date:"2023-04-05"}
特点说明:
- 聚簇索引的叶子节点存储了表中的所有列数据
- 数据按主键值物理有序存储
- 一张表只能有一个聚簇索引
- 二级索引(辅助索引)数据存储示意图
二级索引(idx_dept_salary)的B+树结构:
[HR,7500] -- 根节点(索引列值)
/ \
[HR,7000] [IT,8500] -- 内部节点(索引列值)
/ \ / \
[HR,7k] [HR,7.5k] [IT,8k] [IT,9k] -- 叶子节点
叶子节点存储的数据示例:
[HR,7000] -> {department:"HR", salary:7000, id:2} -- 只存储索引列和主键值
[HR,7500] -> {department:"HR", salary:7500, id:6}
[IT,8000] -> {department:"IT", salary:8000, id:1}
[IT,9000] -> {department:"IT", salary:9000, id:5}
特点说明:
- 二级索引的叶子节点只存储索引列(department, salary)和主键值(id)
- 不包含表中的其他列数据(如name, hire_date)
- 如果查询需要其他列的数据,需要通过主键值回表查询聚簇索引
- 一张表可以有多个二级索引
3.2 查询过程分析
3.2.1 使用聚簇索引查询
[主键值] 根节点
/ | \
[主键值] [主键值] [主键值] 中间节点
/ | \ | | \
[完整数据行] [完整数据行] [完整数据行] 叶子节点
- 直接在叶子节点获取完整的数据行
- 只需要一次索引检索
3.2.2 使用二级索引查询
[索引列值] 根节点
/ | \
[索引列值] [索引列值] [索引列值] 中间节点
/ | \ | | \
[索引列值,主键值] [索引列值,主键值] 叶子节点
查询过程分为两种情况:
- 覆盖索引:
- 查询的列都包含在索引列中
- 直接从二级索引的叶子节点获取数据
- 不需要回表查询
覆盖索引是一种特殊的查询优化方式,覆盖索引是指一个索引包含了查询所需的所有列,因此不需要访问表中的数据行就能完成查询。当查询的列恰好都包含在索引中时,查询可以完全在索引层完成,而不需要访问表中的数据行。例如:
-- 创建一个包含name和age的联合索引
CREATE INDEX idx_name_age ON users(name, age);
-- 以下查询可以使用覆盖索引
SELECT name, age FROM users WHERE name = '张三';
- 需要回表:
- 查询的列不全在索引列中
- 先从二级索引找到主键值
- 再根据主键值去聚簇索引中查找完整数据
四、实际案例解析
4.1 表结构和数据示例
-- 创建员工信息表
CREATE TABLE employees (
emp_id INT PRIMARY KEY, -- 聚簇索引
name VARCHAR(50),
department VARCHAR(50),
salary INT,
hire_date DATE,
INDEX idx_dept_salary(department, salary) -- 二级索引
);
-- 插入示例数据
INSERT INTO employees VALUES
(1, '张三', 'IT', 15000, '2022-01-15'),
(2, '李四', 'IT', 12000, '2022-03-20'),
(3, '王五', '销售', 10000, '2022-02-10'),
(4, '赵六', '销售', 13000, '2022-04-05');
4.2 查询场景分析
4.2.1 使用聚簇索引(主键查询)
SELECT * FROM employees WHERE emp_id = 2;
查询过程:
- 从聚簇索引的根节点开始,比较emp_id值
[2]
/ \
[1,2] [3,4]
/ \ / \
[1数据] [2数据] [3数据] [4数据]
- 直接在叶子节点找到emp_id=2的完整数据行:
{emp_id: 2, name: '李四', department: 'IT', salary: 12000, hire_date: '2022-03-20'}
4.2.2 使用二级索引(部门和薪资查询)
- 覆盖索引示例:
-- 只查询索引包含的列
SELECT department, salary
FROM employees
WHERE department = 'IT' AND salary > 13000;
查询过程:
[IT,12000]
/ \
[IT,12000] [销售,10000]
/ \ / \
[IT,12k,2] [IT,15k,1] [销售,10k,3] [销售,13k,4]
- 在二级索引中找到符合条件的记录
- 因为只需要department和salary信息,这些都在索引中,所以无需回表
- 需要回表的查询示例:
-- 查询包含非索引列(hire_date)
SELECT name, department, salary, hire_date
FROM employees
WHERE department = 'IT' AND salary > 10000;
查询过程:
a) 先在二级索引中查找:
找到两条记录:
- {department: 'IT', salary: 12000, emp_id: 2}
- {department: 'IT', salary: 15000, emp_id: 1}
b) 通过获得的emp_id回表查询:
主键索引查询 emp_id=1:
{emp_id: 1, name: '张三', department: 'IT', salary: 15000, hire_date: '2022-01-15'}
主键索引查询 emp_id=2:
{emp_id: 2, name: '李四', department: 'IT', salary: 12000, hire_date: '2022-03-20'}
这个例子清楚地展示了:
- 使用聚簇索引查询时,一次索引查找就能获取完整数据
- 使用二级索引时,如果需要查询索引列之外的数据,需要额外的回表操作
- 合理使用覆盖索引可以避免回表查询,提高查询效率
五、性能优化建议
- 合理使用覆盖索引
- 尽量将常用的查询列加入到索引中
- 避免不必要的回表操作
六、总结
理解聚簇索引和二级索引的区别,关键在于:
-
存储内容的不同
- 聚簇索引存储完整的数据行
- 二级索引只存储索引列和主键值
-
查询方式的不同
- 聚簇索引直接获取数据
- 二级索引可能需要回表查询
-
使用场景的不同
- 聚簇索引适合主键查询
- 二级索引适合索引列的查询和范围查询
问:MySQL聚簇索引和非聚簇索引的区别是什么?
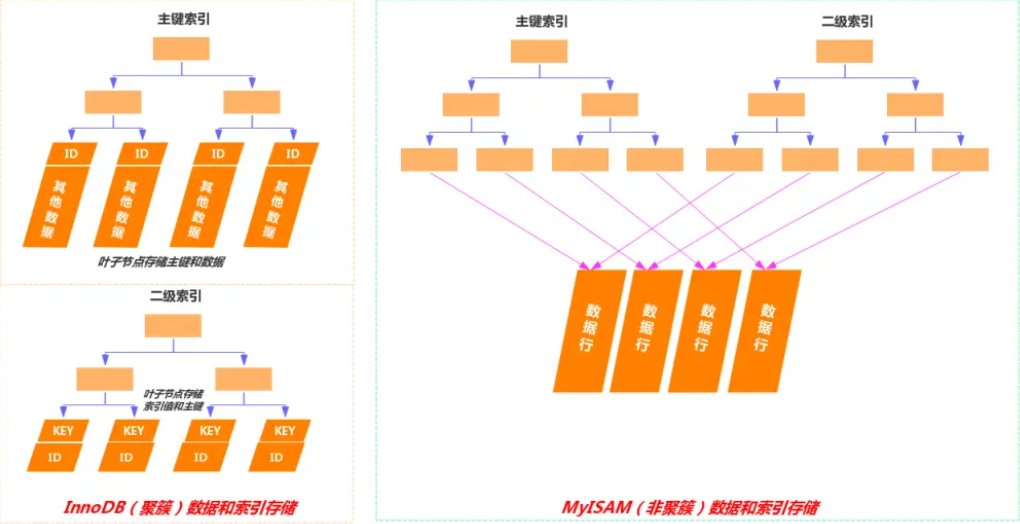
数据存储:在聚簇索引中,数据行按照索引键值的顺序存储,也就是说,索引的叶子节点包含了实际的数据行。这意味着索引结构本身就是数据的物理存储结构。非聚簇索引的叶子节点不包含完整的数据行,而是包含指向数据行的指针或主键值。数据行本身存储在聚簇索引中。
索引与数据关系:由于数据与索引紧密相连,当通过聚簇索引查找数据时,可以直接从索引中获得数据行,而不需要额外的步骤去查找数据所在的位置。当通过非聚簇索引查找数据时,首先在非聚簇索引中找到对应的主键值,然后通过这个主键值回溯到聚簇索引中查找实际的数据行,这个过程称为“回表”。
唯一性:聚簇索引通常是基于主键构建的,因此每个表只能有一个聚簇索引,因为数据只能有一种物理排序方式。一个表可以有多个非聚簇索引,因为它们不直接影响数据的物理存储位置。
效率:对于范围查询和排序查询,聚簇索引通常更有效率,因为它避免了额外的寻址开销。非聚簇索引在使用覆盖索引进行查询时效率更高,因为它不需要读取完整的数据行。但是需要进行回表的操作,使用非聚簇索引效率比较低,因为需要进行额外的回表操作。
#如果聚簇索引的数据更新,它的存储要不要变化
欢迎联系